Относительныеоценкисволшебнымиживотнымиисетками
Мы не умеем оценивать. Я каждый день убеждаюсь в том, что люди не умеют оценивать в абсолютных величинах. Когда я провожу Professional Scrum Master (PSM) класс, то обычно в первый день тренинга после обеда мы играем с участниками в Ball Point Game. Для этой игры я приношу пакет, в котором находятся 204 шарика (подсчитано точно :)). Я даю каждому подержать его в руках, разрешаю даже заглянуть внутрь и потрогать шарики. Затем все дают оценки, записывают на стикерах и передают мне. Разброс получается очень большой. Иногда цифры отличаются на порядок: 40 и 400 шаров.
Пару лет назад мой коллега Сергей Дмитриев написал об очень занимательном исследовании, которое было проведено норвежским институтом Simula Research Lab. Это забавное исследование показывает, что люди так и не научились оценивать в абсолютных величинах. Увы, нам с вами этого не дано.
Но не все так плохо. Не стоит ставить крест на человечестве. Ведь мы довольно сносно можем оценивать в относительных величинах. Давайте разберемся, из чего же состоят стори-поинты или так называемые «попугаи». А затем я опишу упражнение, которое помогает объяснить эту концепцию на практике. Только сложность? Когда я спрашиваю: «что показывают или содержат в себе стори-поинты?», обычно слышу «сложность». Хм… верно, но лишь частично.
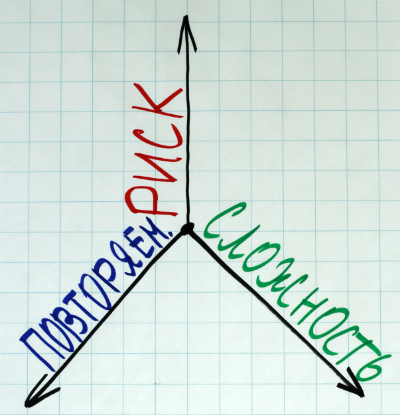
В стори-поинты зашито большое количество параметров. Можно сказать, что это некий аггрегированный gut feeling. Тем ни менее, мне нравится упрощенная модель стори-поинта, основанная на трех параметрах:
- Риск. В каждой задаче есть составляющая риска. Нечеткие требования, неопределенность в технологиях (например, нам лучше использовать API яндекса или гугла в нашем приложении?), зависимости от других команд или поставщиков и т.д. Исключить риск полностью невозможно, но если он зашкаливает, то мы его обычно «вырезаем» с помощью практики, которая называется “spike”. Мы говорим так: «хотим потратить 8 часов на исследование этой проблемы». В результате получаем нужную информацию, возвращаемся к предыдущей задаче и оцениваем.
-
Сложность. Если вы знаете, что такое школьные или студенческие олимпиады по информатике, то вы меня поймете. Часто на них даются задачи, которые можно решить несколькими десятками строк кода, но такой алгоритм и код будут очень сложными для понимания.
-
Повторяемость (или монотонность). Пример монотонной задачи, которая лишена риска и сложности – переписывание от руки «Войны и Мира» Льва Толстого (при условии, конечно, что вы умеете писать :)).
Таким образом, стори-поинт содержит в себе все три параметра, причем в разных пропорциях. Мы пытаемся оценить задачу, полностью отвязавшись от времени. Нас интересует лишь объем (или размер) задачи. К примеру:
Требуется выкопать метр кубический земли. У вас есть два пути. Первый – сделать это лопатой, второй – экскаватором. Какие будут оценки в стори-поинтах в первом и втором случаях?
Правильный ответ: они будут равны. Нас абсолютно не интересует то, что с помощью экскаватора вы добьетесь цели в 10 раз быстрее. Объем работы, который необходимо совершить не меняется.
Связь между временем и относительными оценками. Прямой связи нет. Мы не принимаем длительность задачи при оценке в стори-поинтах. Скажем, senior java developer Вася сделает задачу на 5 SP за два дня, а junior java developer Миша потратит целую неделю. Меняется ли оценка задачи? Нет. Есть лишь две разные скорости, которые мы можем измерить. Это актуально и для команд. Мы меряем скорость, отвязываясь в оценках от времени. Далее, чтобы ответить на извечный вопрос «когда ЭТО будет сделано?», нам остается лишь вспомнить формулу из курса физики. Время равно расстоянию (суммарный объем задач) деленному на среднюю скорость (велосити команды).
Оцениваем относительно других задач. Используя стори-поинты, мы даем оценку задаче, сравнивая ее с другими. Но как определить, сколько стори-поинтов «весит» самая первая эталонная задача, относительно которой мы собираемся проводить дальнейшие оценки? Давайте посмотрим на упражнение, которое я назвал «Относительные оценки с волшебными животными». Читаем когда фигурки животных стали волшебными здесь. Нам потребуется:
-
12-20 различных фигурок животных.
-
Группа людей из 4-6 человек.
-
Стикеры, на которых написаны числа из модифицированного ряда Фибоначчи: 1, 2, 3, 5, 8, 13, 20.
Расставляем животных. Даем группе задание расставить животных в ряд от самого легкого до самого тяжелого в природе. Разговаривать нельзя, двигаем фигурки молча. Ограничиваем активность 3-7 минутами в зависимости от количества фигурок. Затем выдаем стикеры с рядом Фибоначчи и просим группу оценить животных в стори-поинтах. Что из этого обычно получается можно увидеть на фото ниже:

Как раз в тот момент, когда группа связывает животных с рядом Фибоначчи и происходит определение «веса» стори-поинтов. Смотрим короткое видео с упражнением по ссылке.
ОК, это лишь животные. Что делать с реальными задачами? Упражнение с волшебными животными можно использовать и для реальных задач. Очень полезная штука в случае если:
-
Команда плохо понимает, что такое относительные оценки и продолжает пересчитывать все на часы.
-
Команда не понимает, что значат магические цифры ряда Фибоначчи 1, 2, 3… и боится давать оценки.
-
У нас большое количество историй (больше 10) и необходимо оценить все их «скопом». Например, такая потребность часто возникает при планировании релиза.
-
Большая команда или несколько команд одновременно работают над одним продуктом.
-
Нужна «калибровка» для того, чтобы избежать инфляции оценок со временем.

Наши действия очень похожи на действия в упражнении с животными. Просим команду расположить истории (если вы пользуетесь ими) слева направо по возрастанию. Затем расставляем оценки, пользуясь рядом Фибоначчи. Приблизительный результат можно увидеть на фото:

Формируем оценочную сетку. Помещаем оцененные истории на бумажный носитель (можно сделать электронную копию) и бережно храним. В дальнейшем,если нам понадобиться оценить новые истории – мы просто можем подойти к этой сетке и быстро определиться с оценкой, ведь теперь нам есть с чем сравнивать.

А что говорит нам Скрам? Скрам, как и ранее, остается гибким фреймворком, который не навязывает конкретные практики и процессы. Вы можете продолжать пользоваться абсолютными, а можете начать работу с относительными оценками. Главное, чтобы это работало для вас. Не забываем, что разработка ПО в большинстве случаев относится к запутанной области, где не существует лучших или хороших практик, а есть лишь возникающие. Удачных вам оценок.
Условия задачи
Представьте такую ситуацию. Вы — новый Скрам-мастер. Ваша Команда Разработки состоит из системного аналитика, двух разработчиков и двух специалистов по тестированию. Длина Спринта — две недели. Команда работает со сложной системой на старой платформе, поэтому для каждого элемента Бэклога Продукта аналитика, разработка и тестирование попадают в отдельные Спринты. В течение последнего Спринта Команда не успела сделать работу, взятую в Спринт, поэтому на Ретро Владелец Продукта допытывается, кто чем занимался в течение Спринта. Владелец Продукта жалуется, что Команда работает очень медленно. Члены Команды жалуются, что бизнес контролирует и микроменеджит их. Как разрешить взаимное недовольство Владельца Продукта и Команды Разработки? Давайте разбираться.Что происходит
Для каждого элемента Бэклога Продукта аналитика, разработка и тестирование попадают в отдельные Спринты — это означает, что элемент будет готов к выпуску только через три Спринта. В таком случае истинная длина Спринта равна шести неделям — это больше, чем допускает Руководство по Скраму.Максимальная продолжительность Спринта — один календарный месяц. При большем сроке планирования возможны изменения целей, увеличение сложности и рост рисков.Руководство по Скраму Когда Команда редко поставляет готовый Инкремент, то редко получает обратную связь от стейкхолдеров и клиентов. В результате:
- возрастает риск сделать не то, что надо. Способность реагировать на изменения падает;
- стабильность процесса падает, прогнозировать работу сложно. Например, тестирование выявляет дефекты через недели после разработки. Баги обнаруживаются поздно, поэтому объём «поддержки» будет меняться от Спринта к Спринту;
- рабочий процесс перестаёт быть прозрачным.
Решение
Скрам-мастер не может решить проблему самостоятельно, но может помочь своей Команде следующим образом:- объяснить описанную выше системную динамику и её вредные последствия. Скрам-команда должна понимать, что правило Скрама про Done Increment каждый Спринт — это естественное системное решение их проблемы;
- помочь сформулировать или пересмотреть минимальный DoD, который может быть выполнен в течение Спринта и который обеспечит готовность Инкремента к релизу;
- научить Команду Разработки правильно декомпозировать элементы Бэклога. Небольшие элементы в Бэклоге Продукта способствуют ранней поставке, оптимизации ценности Продукта и улучшению потока работы;
- помочь договориться взять в следующий Спринт хотя бы один небольшой элемент Бэклога, но довести его до состояния Done;
- визуализировать поток работы. Прозрачность — залог успеха;
- устранить простои в работе. Для этого Скрам-мастер обучает Команду хорошим инженерным практикам, например, общему владению кодом, стимулирует развитие T-shaped или E-shaped людей в Команде, заключает командные соглашения;
- объяснить Владельцу Продукта, что причина задержек — технический долг и убедить его выплатить.
Итоги
Готовый Инкремент в конце Спринта — это важнейшие правило Скрама, которое помогает избежать роста рисков, потери предсказуемости и гибкости. Описанные причинно-следственные связи полезно знать, чтобы понимать, почему Скрам требует соответствующий DoD, готовый к релизу Инкремент каждый Спринт. Следующие действия могут помочь в достижении этой цели:- декомпозиция работы на небольшие PBI;
- визуализация потока работы в Спринте и поиск основных узких мест;
- устранение «простоев» работы с помощью командных соглашений, хороших инженерных практик и развития T-shaped или Е-shaped людей;
- планомерная ликвидация технического долга.
Справедливо внутри одного спринта. Что делать во втором ? Нужно сравнивать с историями из первого. Как ?